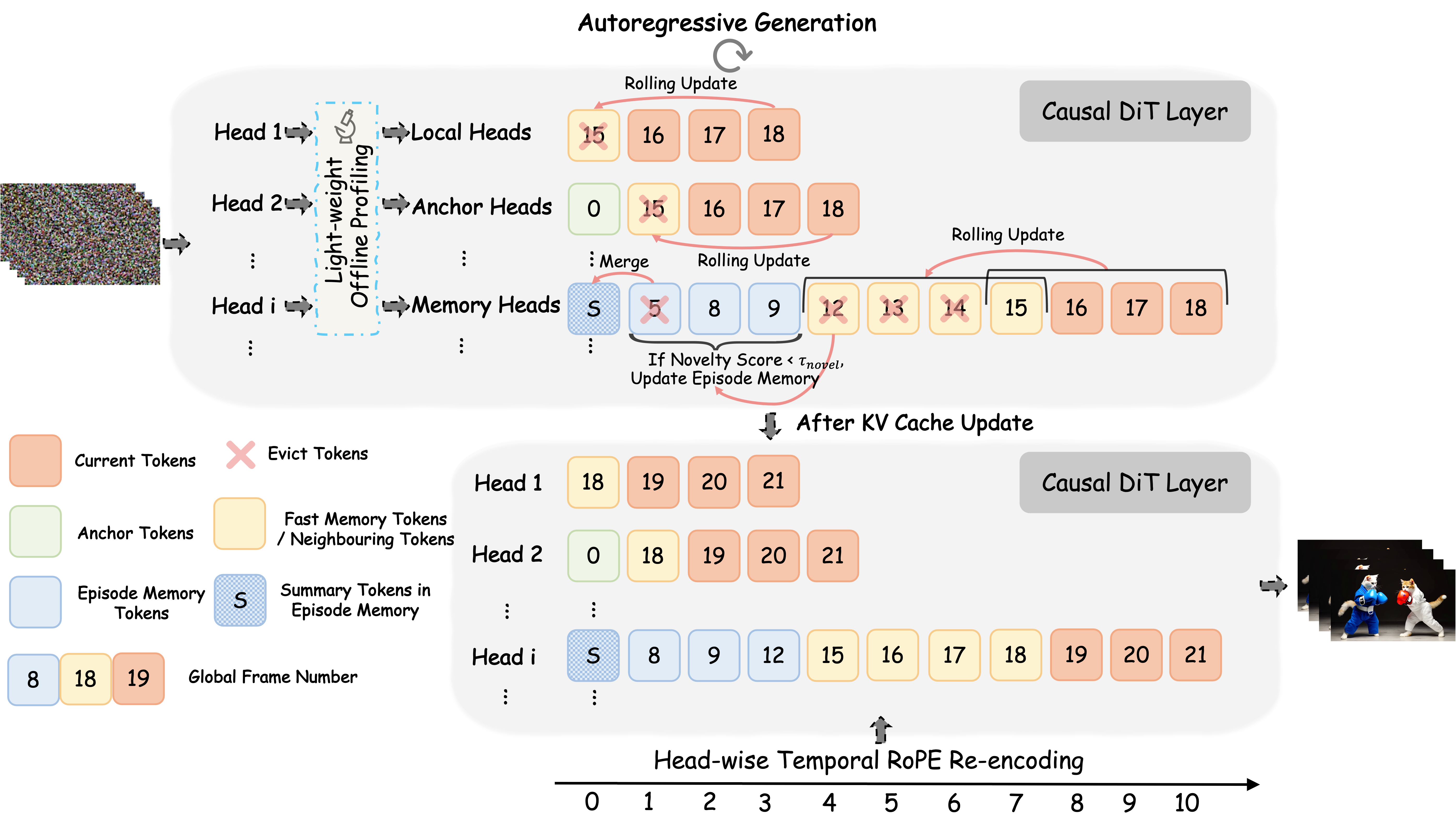
Key Discovery: Attention Head Heterogeneity
We discover that attention heads in AR video diffusion transformers serve functionally distinct roles, yet existing methods treat them uniformly, leading to suboptimal KV cache allocation. We identify three distinct head types:
Local Heads
Focus on the current block and its immediate neighborhood for detail refinement and short-range motion continuity.
Anchor Heads
Exhibit elevated first-frame attention, using the initial frame as a structural anchor to prevent visual collapse.
Memory Heads
Attend broadly across the full context to capture narrative elements and sustain long-range memory.
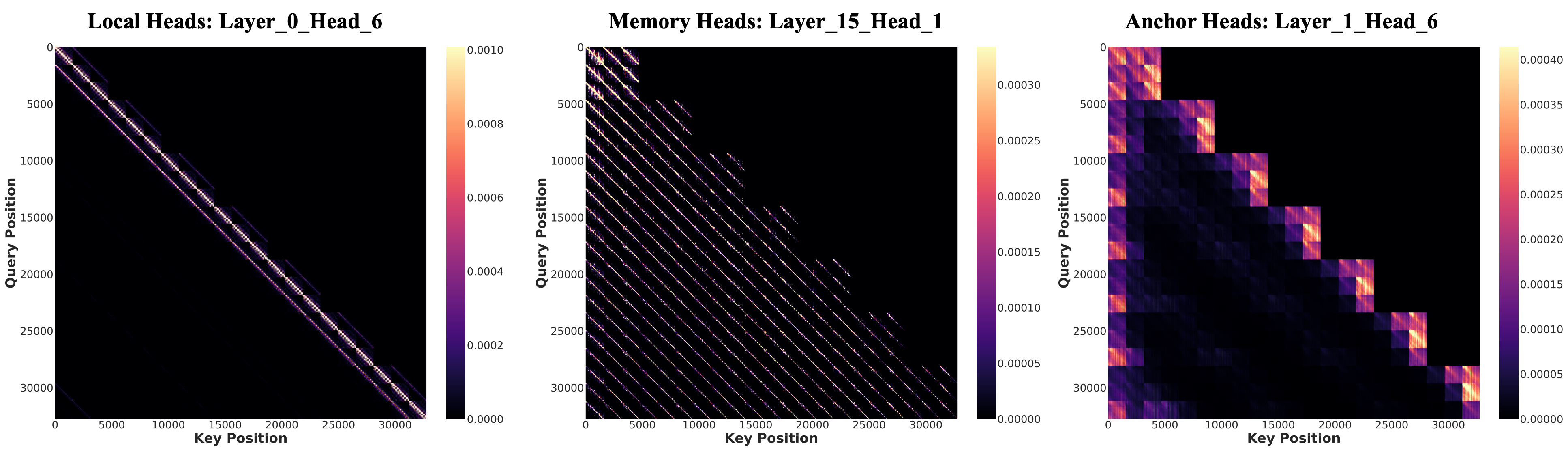
Representative attention patterns for different attention heads.
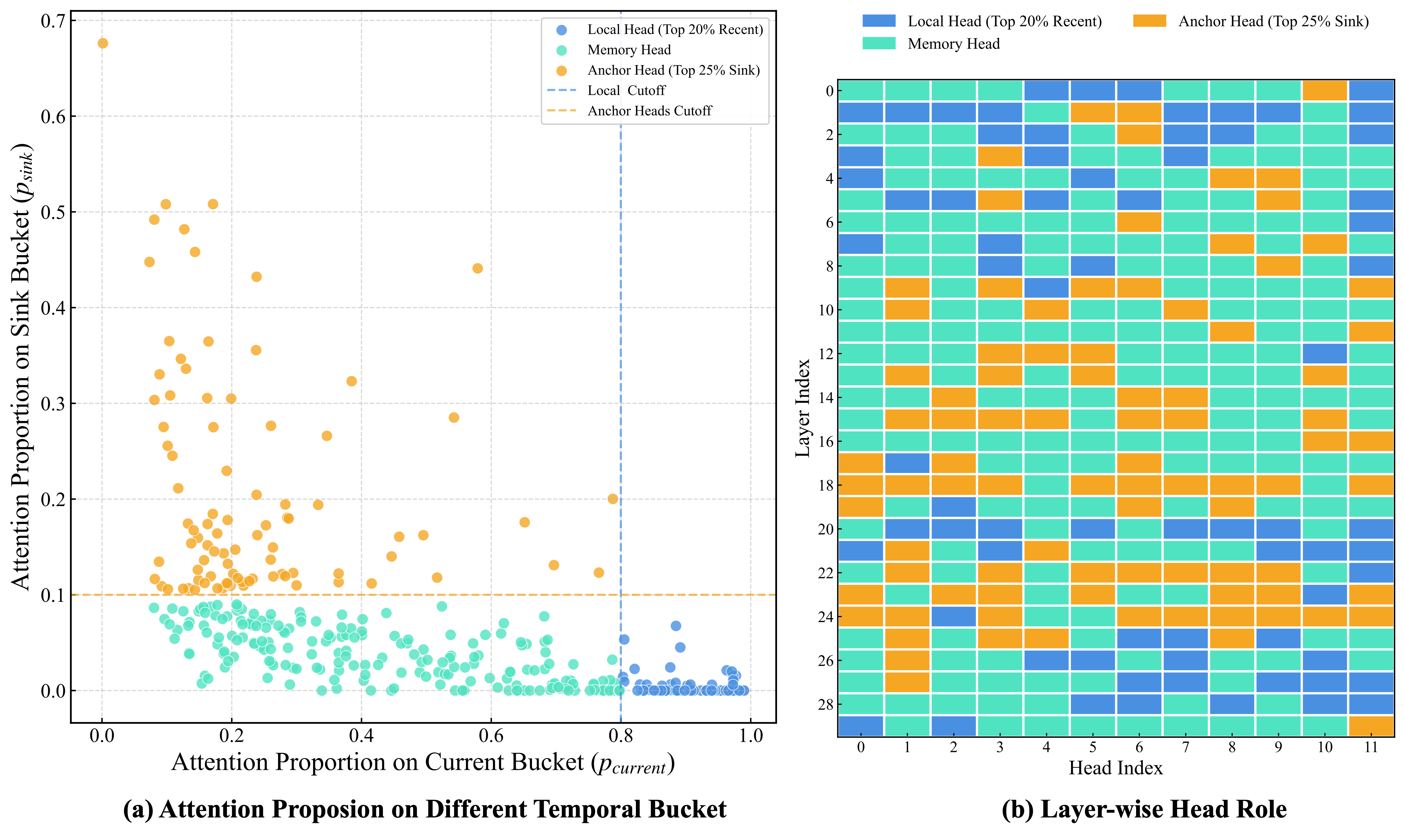
Attention proportion for each head shows clear clustering into local, anchor, and memory heads.